今天我们要为大家推荐一篇来自IEEE S&P 2024的研究论文Efficient Detection of Java Deserialization Gadget Chains via Bottom-up Gadget Search and Dataflow-aided Payload Construction,由复旦大学系统软件与安全实验室和Johns Hopkins university的研究人员联合完成。

在这篇论文中,作者设计实现了一个自动化检测Java反序列化链的工具——JDD(Java Deserialization Vulnerability Detector的缩写),它能够有效地检测Java反序列化漏洞,找出gadget并链接成完整的反序列化链。说起反序列化,这个是一个方便但是危险的特性,在OWASP 2017 Top 10 安全风险中,不安全的反序列化排名第七。特别地,在Java语言中,序列化和反序列化可以很方便的存储和交换Java对象,但也面临着一个众所周知的严重安全漏洞:Java对象注入(Java Object Injection, JOI)。利用JOI漏洞,攻击者可以注入一个恶意构造的序列化对象,从而调用一连串外部无法直接调用的Java方法(本文中称为gadget),最终造成严重的攻击后果(例如RCE等)。

过去已经有许多研究聚焦JOI漏洞,并提出了多种检测方法。但是大部分工作通常采用自上而下的静态方法,检查从source到sink的所有潜在路径,并检查可能涉及的gadget。然而,这样的搜索策略往往会导致路径爆炸,尤其是当反序列化链中涉及到equals和put等常见的Java方法。实验表明,像ODDFuzz等工具采用的静态分析方法甚至无法分析一个3.6MB的小型Java应用程序,同时,有一部分工具仅进行了静态分析,没有通过动态测试(例如fuzz)进行验证,误报率较高。
在本文中,作者通过分析JOI漏洞成因和之前工作的不足,为JDD自动化分析工具采用了自下而上的搜索方式(从 sink到source),解决静态gadget搜索中的路径爆炸问题,显著减少了搜索时间。此外,JDD构建了一种注入对象构造图(Injection Object Construction Diagram, IOCD),用来更好地描述Java对象(特别是其中的成员变量),从而更好地构建注入对象字段间的数据流依赖性。下图是一个实际的例子,作者指出,传统的对象层级结构分析(下图右)建模不够细致,因此会影响分析效果:
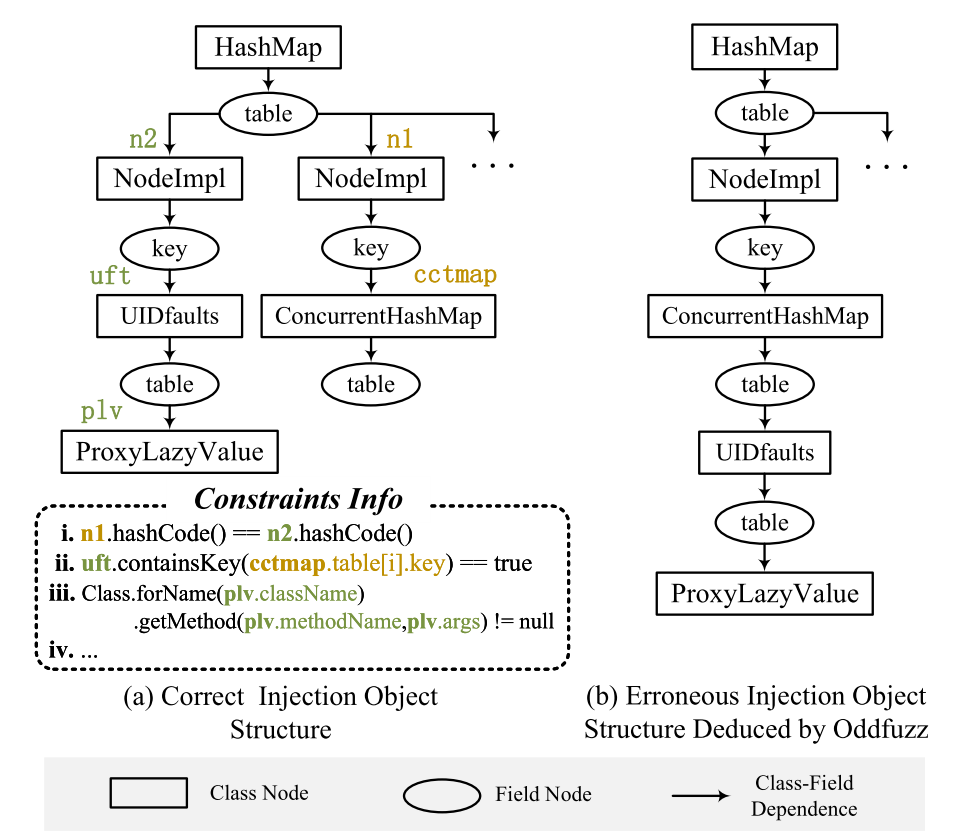
JDD通过引入IOCD,更细致地描述了数据流分析中的对象结构,因此在后面的exploit攻击过程中,能够很好地处理注入对象可能是复杂结构的情况。
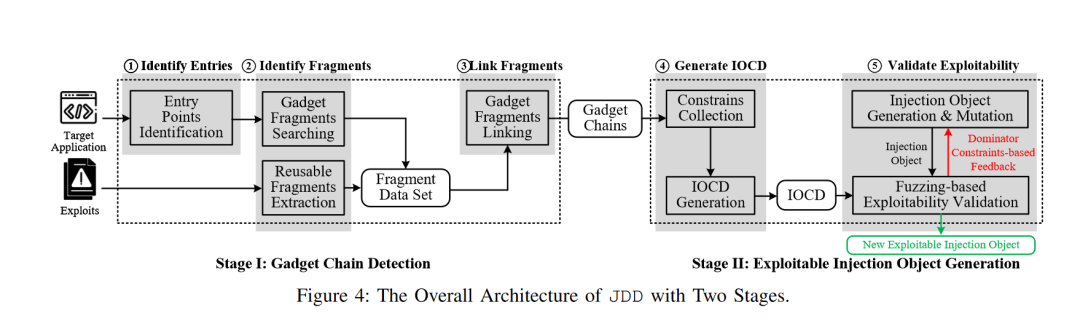
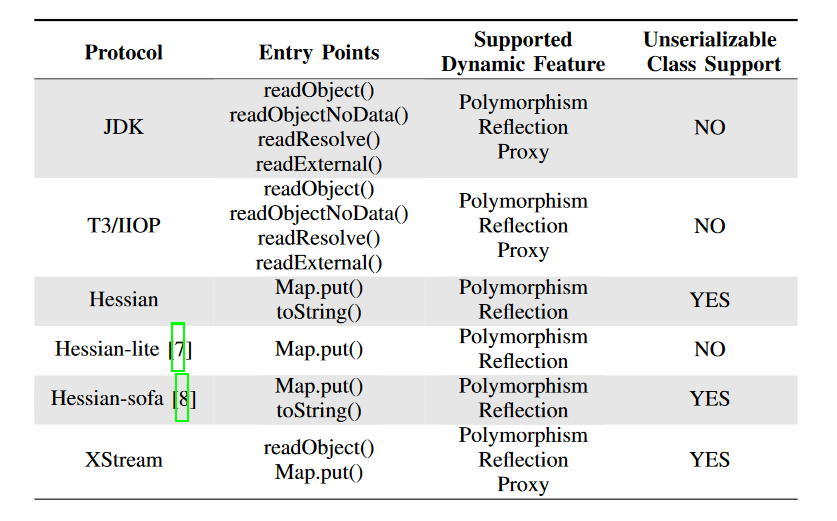
上图展示了JDD的整体工作流程,这个工作流程分为两个主要的步骤。在第一个步骤中,JDD首先寻找反序列化的入口点。入口点可以分为两类:Java 提供的反序列化方法、第三方反序列化框架(Hessian等)提供的方法。如下表所示,JDD通过识别具体的方法名,提取到反序列化的入口点。
接下来,JDD要去识别所谓的“gadget片段”(gadget fragment),如果你熟悉基本块也就是basic block的概念,这个gadget片段也很容易理解,它就相当于是把gadget看成指令所组成的基本块,也就是一系列的gadget,没有分支跳转,可以连续执行下去。为了识别gadget片段,JDD用静态代码分析技术识别Java类的继承层次及其重载方法,同时也分析Java中的多态、动态代理(Dynamic Proxy)和反射(Reflection)等特征,尽可能多地收集gadget片段;然后采用自下而上的方法对gadget片段进行链接,想办法得到一个gadget chain。
在实际分析中,gadget片段主要有三种类型:
source 片段: gadget片段的头部是source
自由状态片段:gadget片段的头部的头部和尾部都是动态方法调用
sink 片段:gadget片段的尾部是sink
JDD 依次链接一个source片段和多个自由状态片段以及一个sink片段,在链接的同时也会会考虑污点传播的要求和方法调用条件。
完成了上述工作,JDD正式进入到工作流程的第二个步骤,即生成exploitable injection object。前面说过,JDD通过使用IOCD这种描述,能够更好地执行数据流分析。为了得到IOCD信息,JDD会首先提取如下一些信息:
变量类型:Java 中一部分成员变量的类型为 Object,但在利用过程中不能为任意类。通过对已链接的 gadget 片段进行自顶向下的推断:对于每个片段,JDD 使用数据流分析来确定哪个变量与下一个片段相关联,然后使用后续片段的头部的方法来确定变量的实际类型
条件分支约束:JDD 将不同执行路径共享的约束标记为支配者(dominator),即所有执行路径受到这些约束限制。在数据流跟踪过程中,JDD 会同时收集与变量相关的条件分支约束,识别约束中检查的变量是否可能被污染。为了确保利用过程中不抛出异常,JDD 会额外添加一些约束
变量依赖约束:sink 点需要能够控制相关变量注入 payload。JDD 会分析变量之间的依赖关系从而确定 sink 点的变量是否可控
提取到这些信息后,JDD 开始构建IOCD: 将反序列化链中所有实例化的对象作为 ClassNodes , ClassNodes 中存储变量相关信息(上一步提取的数据)FieldNodes。基于约束,ClassNodes 通过 FieldNodes 使用有向边相互连接,从而表现出实例化对象之间的层次关系。
JDD工作流程的最后一步是基于IOCD和gadget chain来开展fuzzing test,通过IOCD提供的信息,生成具有正确层次结构的对象,同时考虑变量之间的约束,执行比较高效的fuzz:JDD从根 ClassNode 节点开始,对每个字段节点执行 BFS 遍历。JDD 将提取 FieldNode的支配者约束,并调用约束求解器生成适当的值,然后将这些值分配给相应的变量。如果变量之间存在双向边,则表示存在约束依赖关系。作者表示,IOCD的使用极大提高了fuzz的效率,这是因为:
可选择变量范围得到了限制
通过约束信息减少了变异(mutation)空间
变量依赖关系以及嵌套对象结构得到了充分利用
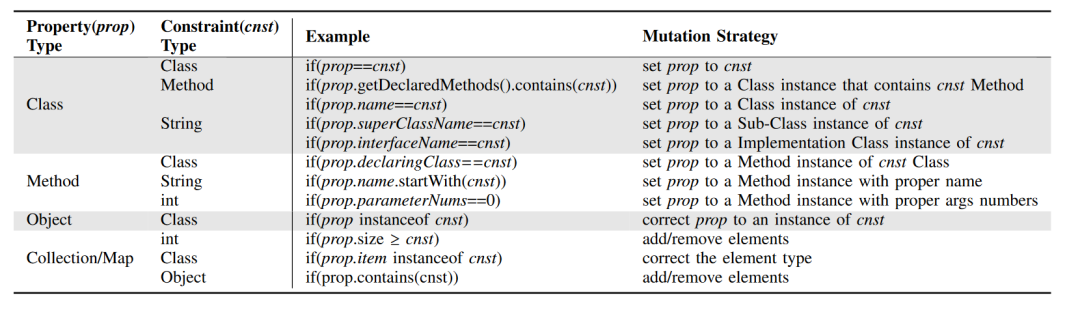
而fuzz的具体变异策略如下图所示,具体细节请参考原文:
通过这些改进,JDD在真实世界的漏洞挖掘中体现了很好的效果——在6个real world Java应用中发现了127个0day,并且拿到了6个CVE编号。
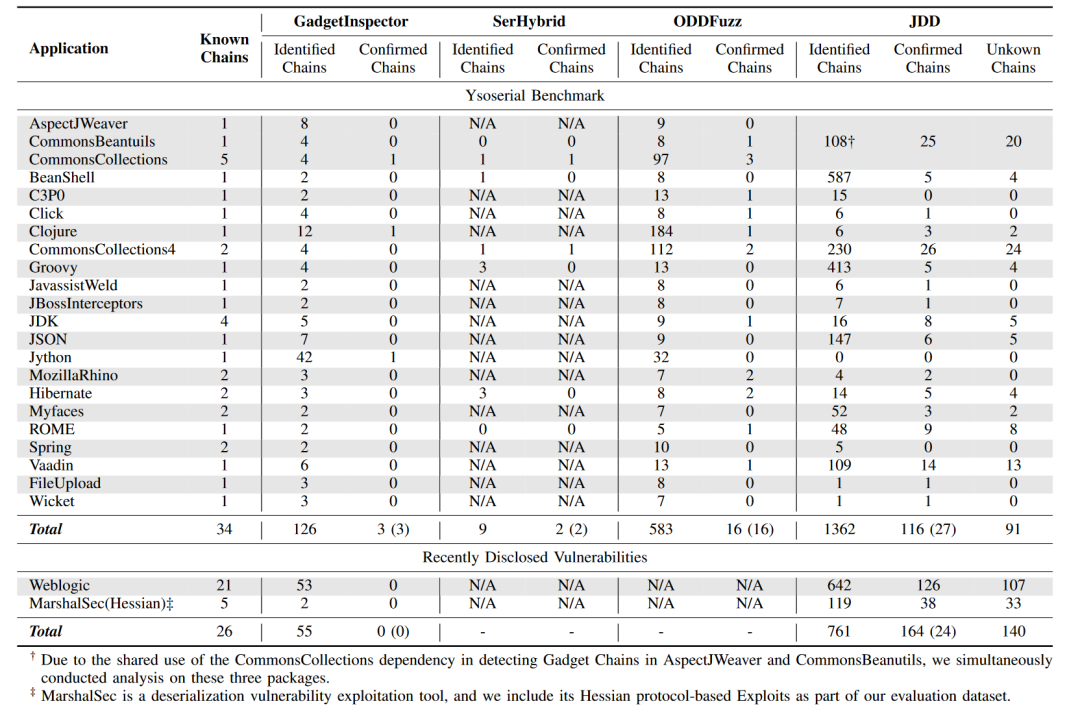
作者使用GadgetInspector、SerHybrid、ODDFuzz和JDD对常用的Java程序进行安全分析,结果如下表所示。可以看出,JDD能够更有效地检测出反序列化链,能够识别出27种已知反序列化链和91种未知反序列化链,效果远好于现有工具,
论文:https://secsys.fudan.edu.cn/_upload/article/files/8a/3c/d8d0e5a142dbbfaa39a58edc76b0/88ab6956-5447-4e4c-8ad8-6785c3fec057.pdf