今天的论文推荐是来自浙江大学区块链与数据安全全国重点实验室投稿的该组在 CCS 2024上发表的最新工作ERASER: Machine Unlearning in MLaaS via an Inference Serving-Aware Approach

Machine Unlearning
Machine Unlearning 是当前机器学习隐私保护领域的前沿热点,根据 Machine Unlearning Paper List[1]的统计,自2021年以来,该方向每年产出的论文数量都超过此前历年总和,呈现指数增长态势。
如此爆发性的增长部分得益于世界各国相继颁布了各自的数据保护法规,比如欧盟的《通用数据保护条例》(European Union’s General Data Protection Regulation, GDPR)、美国的《加州消费者隐私法案》(California Consumer Privacy Act , CCPA)和中国的《个人信息保护法》等。这些法案不约而同地规定了用户的删除权或被遗忘权(The Right to be Forgotten),即用户有权要求网络服务提供者删除所有个人数据。
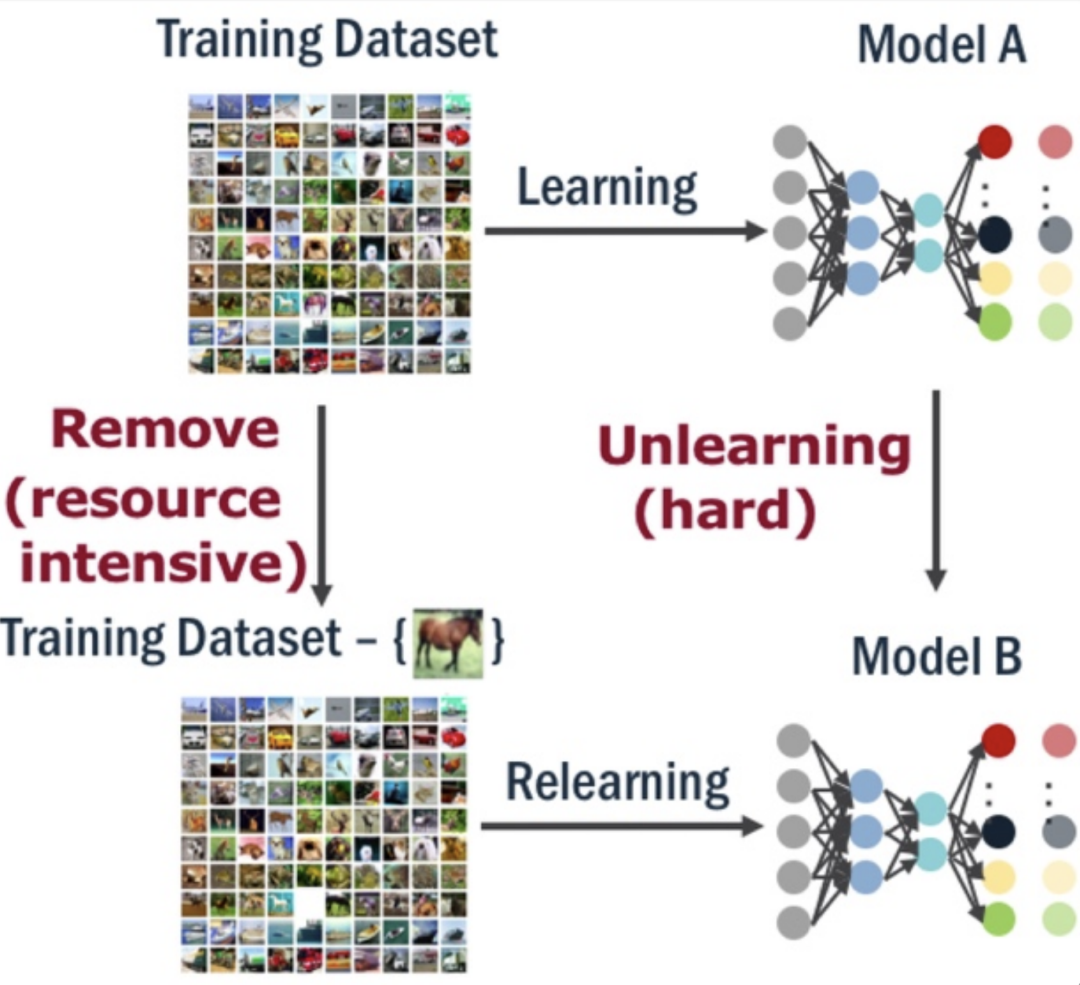
从数据库中删除用户个人数据并不困难,但如果这些数据已经被用于模型训练,事情就变得棘手起来。经过训练的模型参数可以被视作对训练数据的一种编码,攻击者可以通过发起成员推理攻击(Membership Inference Attack)逆向恢复出训练数据,因此从模型中“删除”这些数据也是必要的。Machine Unlearning 的目标就是从已训练好的模型中消除特定训练数据的影响,从而实现彻底的“数据删除”。
最容易想到的方法是将这些数据从训练集中移除,然后“从零开始”重新训练,但鉴于如今日益膨胀的模型规模,“从零开始”的成本难以接受;另一种思路就是精确地量化这些数据对模型参数的影响并将其消除,但由于深度学习模型“臭名昭著”的黑盒特性,这也是一项几乎不可能完成的任务。
Machine Unlearning 需要克服这些难点,以尽可能低的成本消除特定数据对模型的影响。这项技术不仅可以满足个人用户删除隐私数据的需求,也可以用于抹除未经许可的版权数据;在数据投毒攻击或大语言模型对齐(LLM Alignment)的场景中,Machine Unlearning 还会被用来删除 Poisoning/Toxic Training Data 以实现“模型消毒”。
Sharded, Isolated, Sliced, and Aggregated
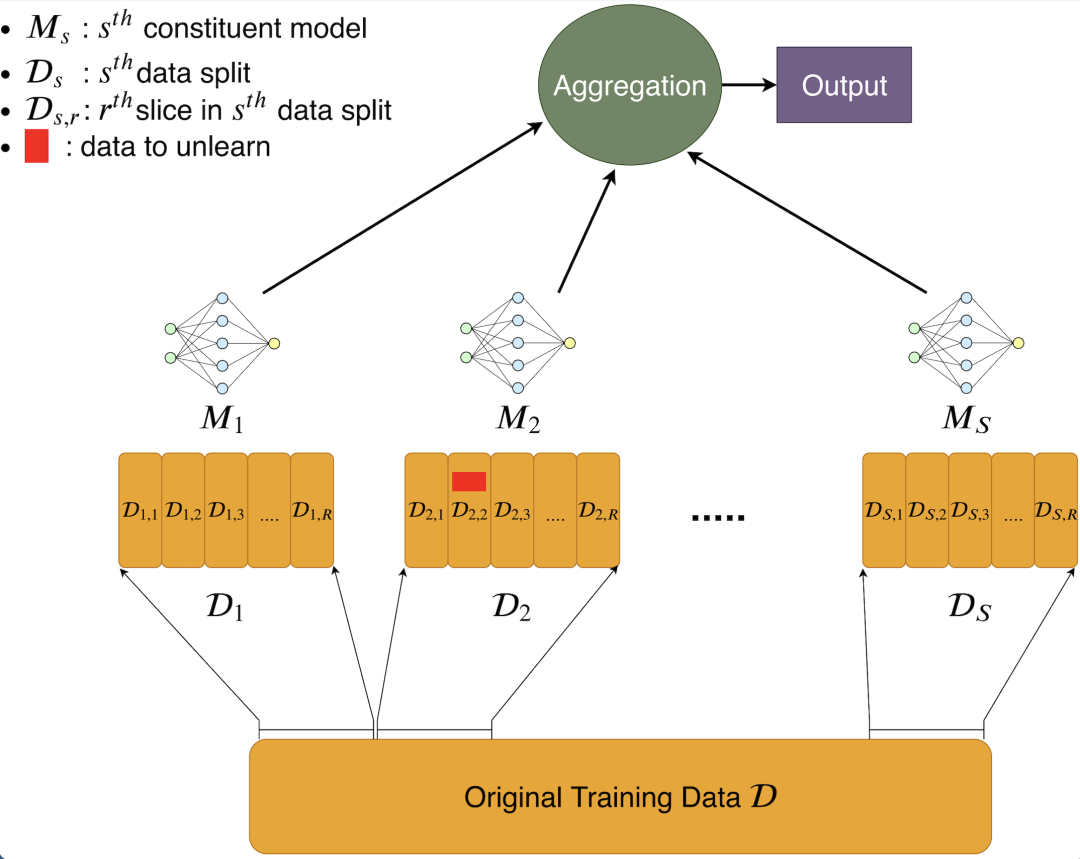
Machine Unlearning 的技术路线大致可分为两种:Exact Unlearning 和 Approximate Unlearning:前者要求经过 Unlearning 处理后的模型与完全重训练的模型严格相同(更严谨的说法是,这两个模型的参数服从同一个概率分布);后者则只要求这两个模型近似相同,以换取更低的计算成本,近似程度可以借鉴差分隐私中的
本文所走的是第一条技术路径。该路径最经典的工作是发表在 IEEE S&P 2021 的论文Machine Unlearning[2],这篇论文提出了一种名为 Sharded, Isolated, Sliced, and Aggregated (SISA) 的方案,核心思路就是通过数据分区限制单条数据的影响范围,从而减少模型更新的计算量。
Machine Unlearning in MLaaS
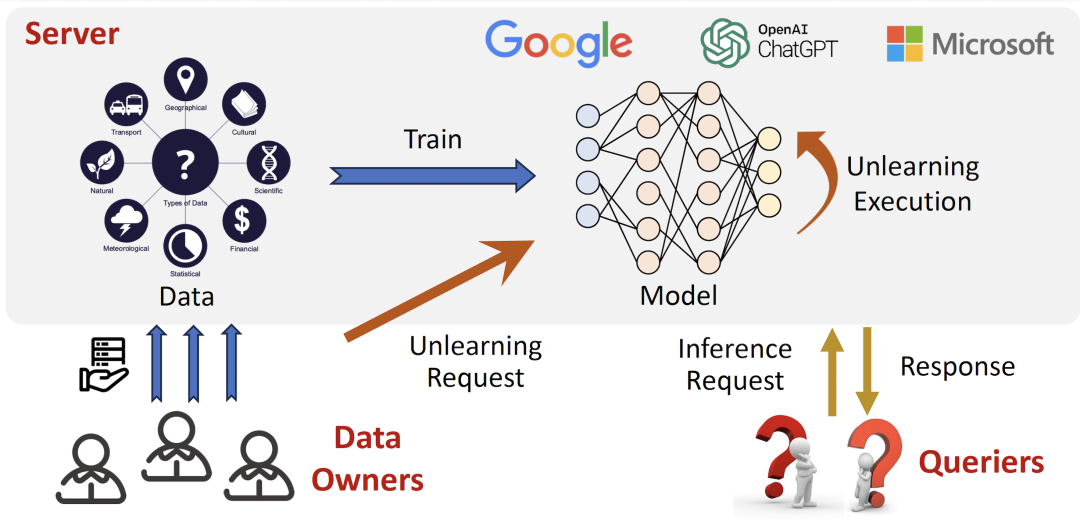
现如今的机器学习模型通常被部署在服务器端(Server)以 ML-as-a-Service (MLaaS) 的形式为用户(Querier)提供推理服务,但包括 SISA 在内的现有工作大多局限于遗忘机制设计及其效率提升,而忽略了如何将其嵌入到实际的模型推理服务流程中。其中最核心的问题就是推理请求(Unlearning Request)与遗忘请求(Unlearning Request)的调度逻辑,一些拍脑门的简单思路往往会导致意想不到的灾难后果,比如以下两种:
Unlearning-request-first
第一种策略以数据合规为第一要义,一旦收到 Data Owners 发来的 Unlearning Requests,就暂停推理服务优先更新模型,完成后再恢复对 Inference Request 的响应。显然攻击者只要在早期伪装为 Data Owners 贡献训练数据,就可以在服务阶段通过连续提交 Unlearning Requests 阻塞推理服务。如果使用模型需要经历漫长的等待,用户很快就会弃之而去。
Inference-request-first
第二种策略则刚好相反,Server 在收到 Unlearning Requests 后继续用旧模型提供推理服务,满足特定条件(如 Request 数量、挂起时间)后再用一次更新集中处理积攒的 Unlearning Requests 。另一种更常见的变种是在收到 Unlearning Requests 后立即在后台更新模型,更新完成后与旧模型切换。它们的问题在于 Server 收到 Unlearning Requests 后仍在使用未经更新的旧模型提供推理服务,导致被要求删除的数据继续暴露在成员推理等攻击的威胁之下,违背了数据合规条款中对 “immediately erasure“ 的规定。如果要删除的数据是毒数据或未经许可的版权数据,每一秒的延迟都可能导致更大的损失。

ERASER
收到 Unlearning Request 后不及时更新模型之所以会造成安全风险,本质原因在于特定训练数据的存在与否可能会导致模型对同一个样本给出不同的推理结果,黑盒场景下的安全风险都源自这种不一致(inconsistency)。如果能确保模型更新前后对同一个 Inference Request 的推理结果是一致的,就可以在推迟模型更新的同时规避安全风险。但验证一致性的前提是获知模型更新后的推理结果,这显然与推迟模型更新的目标相矛盾,就好像我们需要一把打开宝箱的钥匙,而唯一的钥匙正被锁在宝箱中。

为了逃离这种窘境,这篇文章利用了 SISA 内生的结构特质,提出了一套新的框架 ERASER: machinE unleaRning in MLaAS via an inferencE seRving-awaer approach,其中最关键的设计是推理一致性验证机制,该机制可以在不实际执行模型更新的前提下验证模型更新前后对特定样本的推理结果是否一致。如果一致,就可以在不引入任何额外的安全风险的情况下推迟对当前 Unlearning Request 的处理,所有被推迟的 Unlearning Requests 可以用一次更新集中处理,以节约时间与算力成本。

该一致性验证机制建立在 SISA 的 “Aggregated” 结构之上,即最终推理结果是由多个子模型的推理结果以投票的方式 “Aggregate” 而来。每当 Server 收到 Inference Request,根据此时尚未处理的 Unlearning Requests 情况可以将所有子模型按是否受影响分为两类。类比到选举投票的场景中,不受这些 Unlearning Requests 影响的子模型相当于 “已投票选民”,而会受影响的则是“摇摆选民”。如果候选人中的领跑者领先幅度大于“摇摆选民”的数量,该候选人就可以提前宣布胜选。回到我们的场景中,“提前宣布胜选”就是一致性得到验证。
Design Options and Variants of ERASER
解决了模型更新是否可以推迟的问题,还不足以构建一套完整的调度策略。本文针对策略设计中的几个关键变量提供了不同的设计选项,以满足不同的 MLaaS 各自的服务水平目标(Service Level Objective, SLO)。
这些关键变量包括
是否同时维护训练环境与推理环境
模型更新的时机选择
如何处理非一致推理请求
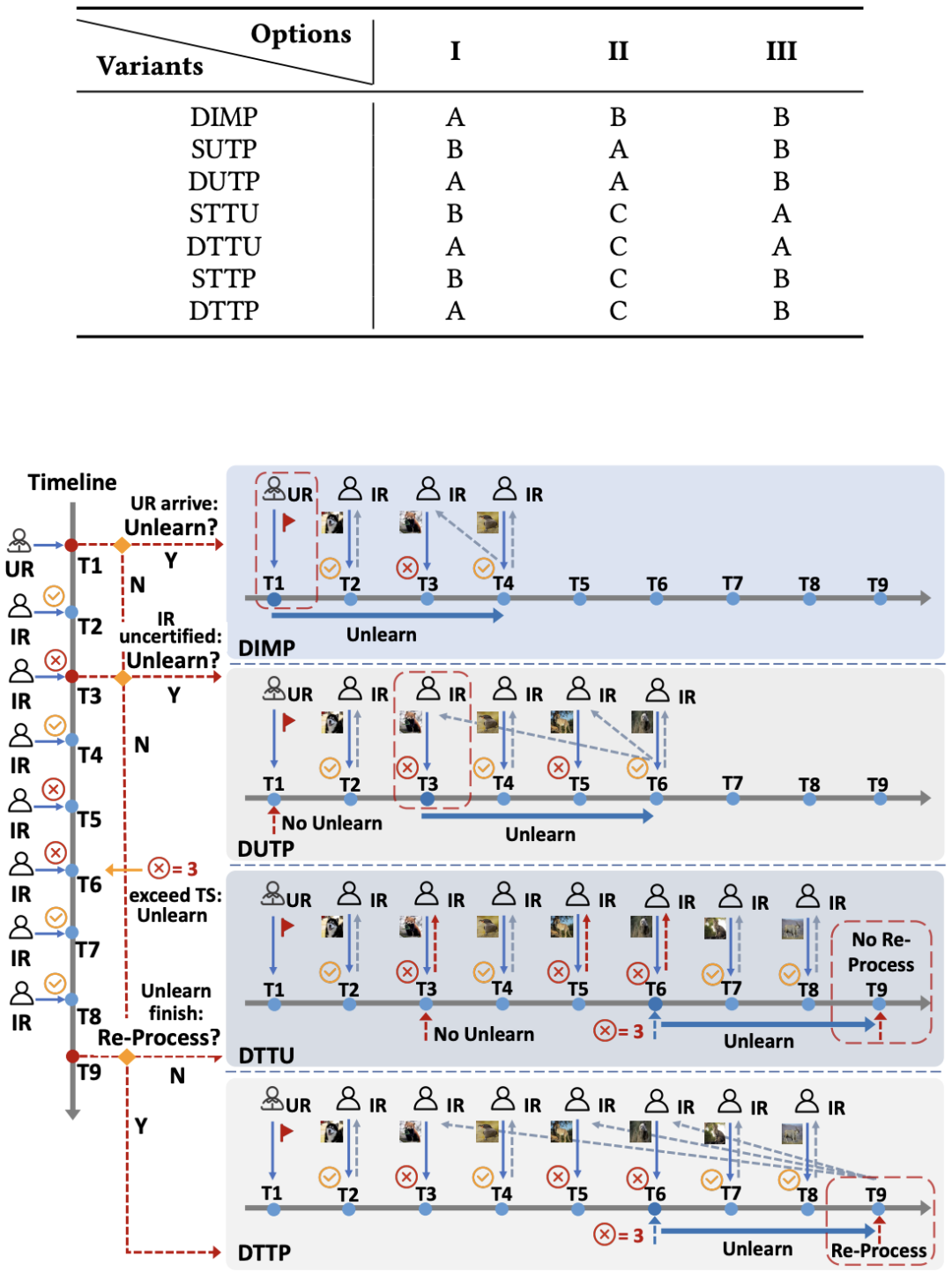
基于这些选项,这篇文章在 ERASER 框架下提供了 7 种不同的 Variants,以实现在推理速度、资源消耗和隐私保护等不同维度间的平衡。
Evaluation
根据在四种不同的数据集及相应模型架构上进行的实验表明,相比于无一致性验证机制的基准方法,ERASER 的推理延迟降低了 99%,计算开销降低了 31%,且不会引入额外的隐私与安全风险。
论文原文:https://arxiv.org/abs/2311.16136
参考链接
Machine Unlearning Paper List: https://github.com/jjbrophy47/machine_unlearning
Machine Unlearning: https://arxiv.org/abs/1912.03817
投稿作者简介:
胡宇轲,浙江大学网络空间安全学院博士研究生,导师为秦湛老师,研究方向为数据安全与隐私、可信机器学习。
个人主页:https://yukehu.github.io/